
《西游降魔》里面的《儿歌三百首》里面有首儿歌叫做《春天在哪里》
歌词是这种:
春天在哪里
春天在哪里
春天就在小朋友的眼睛里
通过俺的渣英语翻译之后是这种:
where spring is
where spring is
the fucking spring is
in javatar's eyes
yo
yo
check it out
我相信。java程序猿已经意识到我说的春天是什么了:)
只是spring跟我们如今说的东东有关系么?临时还没有-_-b
言归正传,開始我们上一章节所说的,把问题搞复杂点儿。
我们如果这个搜索业务须要lucene和mysql的支持。
通过lucene的检索获得文档ID。然后依据ID去mysql数据库查询,获得文档的标题和文本内容。
让我们从需求開始,首先操作 SearchServiceInRealBiz 类:
package cn.com.sitefromscrath.service;import java.util.ArrayList;import java.util.List;import cn.com.sitefromscrath.entity.Result;public class SearchServiceInRealBiz implements SearchService { public List search(String keywords) { int[] idlist = findDocIDs(keywords); List results = getResultsByDocIDs(idlist); return results; }} 当然,你会看到你的eclipse会有错误提示信息: 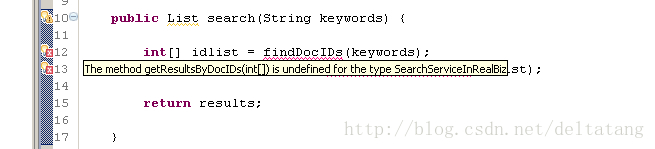
由于这两个方法未定义。
可是没有关系,eclipse本身自带工具,
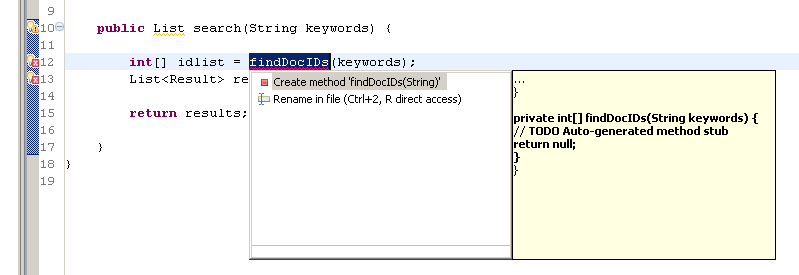
自己主动生成的代码是这样子的:
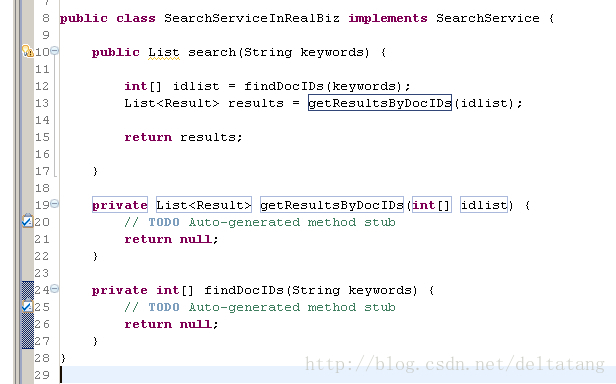
实现他们就好啦:)
我们依照先前的开发流程。给出模拟实现先:
package cn.com.sitefromscrath.service;import java.util.ArrayList;import java.util.List;import cn.com.sitefromscrath.entity.Result;public class SearchServiceInRealBiz implements SearchService { public List search(String keywords) { int[] idlist = findDocIDs(keywords); List results = getResultsByDocIDs(idlist); return results; } private List getResultsByDocIDs(int[] idlist) { List results = new ArrayList (idlist.length); for(int i = 0; i < idlist.length; i++) { int id = idlist[i]; String title = "result " + id; String content = "something.................."; results.add(new Result(title, content)); } return results; } private int[] findDocIDs(String keywords) { return new int[]{1, 2, 3, 4}; }} 请记住。每一步我们都应该去做測试,这里就不一一赘述。 比方,我们能够把BeanFactory run一次。看看main方法的输出会不会发生非预期的变化。
如今。尽管我没有执行tomcat查看网页,可是我能肯定,网页所展示的内容一定是正确的。
因为java程序猿的本性发作,我认为写一个DAO层,然后。。。当然是接口和实现分离虾米的。
。
。
lucene的实现(模拟阶段):
接口:
package cn.com.sitefromscrath.dao;public interface LuceneDAO { public int[] findDocIDs(String keywords); } 实现: package cn.com.sitefromscrath.dao;public class LuceneDAOMock implements LuceneDAO { @Override public int[] findDocIDs(String keywords) { return new int[]{1, 2, 3, 4}; }} Mysql的实现(模拟阶段): 接口:
package cn.com.sitefromscrath.dao;import java.util.List;import cn.com.sitefromscrath.entity.Result;public interface MysqlDAO { public List getResultsByDocIDs(int[] idlist); } 实现: package cn.com.sitefromscrath.dao;import java.util.ArrayList;import java.util.List;import cn.com.sitefromscrath.entity.Result;public class MysqlDAOMock implements MysqlDAO { @Override public List getResultsByDocIDs(int[] idlist) { List results = new ArrayList (idlist.length); for(int i = 0; i < idlist.length; i++) { int id = idlist[i]; String title = "result " + id; String content = "something.................."; results.add(new Result(title, content)); } return results; }} 然后,我们把 SearchServiceInRealBiz 的代码从新组织一次。将: package cn.com.sitefromscrath.service;import java.util.ArrayList;import java.util.List;import cn.com.sitefromscrath.entity.Result;public class SearchServiceInRealBiz implements SearchService { public List search(String keywords) { int[] idlist = findDocIDs(keywords); List results = getResultsByDocIDs(idlist); return results; } private List getResultsByDocIDs(int[] idlist) { } private int[] findDocIDs(String keywords) { }} 替换为: public class SearchServiceInRealBiz implements SearchService { public List search(String keywords) { // int[] idlist = findDocIDs(keywords);// List results = getResultsByDocIDs(idlist); LuceneDAO luceneDAO = new LuceneDAOMock(); int[] idlist = luceneDAO.findDocIDs(keywords); MysqlDAO mysqlDAO = new MysqlDAOMock(); List results = mysqlDAO.getResultsByDocIDs(idlist); return results; }} 測试,stdout / eclipse console 输出无误。 [result 1]something..................[result 2]something..................[result 3]something..................[result 4]something..................
当然。我们相同会发现一个问题,我们如今的类是模拟的数据啊,以后怎么切换呢?
还好,有工厂。既然我们在工厂里切换了
SearchService那么,
LuceneDAO MysqlDAO相同能够在那里处理,于是,相同运行我上面提到的流程,
从需求開始,我须要一个什么样的方法,那就先定义什么方法,然后利用eclipse工具生成方法的骨架 method skeleton,然后实现它。
首先改写 SearchServiceInRealBiz :
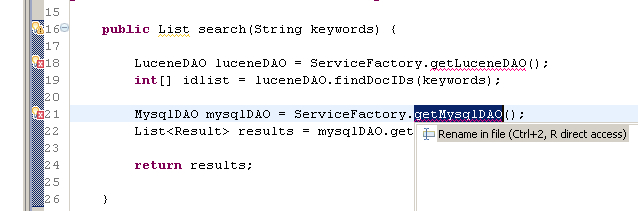
然后,实现方法骨架:
package cn.com.sitefromscrath;import java.util.List;import javax.xml.rpc.ServiceFactory;import cn.com.sitefromscrath.dao.LuceneDAO;import cn.com.sitefromscrath.dao.LuceneDAOMock;import cn.com.sitefromscrath.dao.MysqlDAO;import cn.com.sitefromscrath.dao.MysqlDAOMock;import cn.com.sitefromscrath.entity.Result;import cn.com.sitefromscrath.service.SearchService;import cn.com.sitefromscrath.service.SearchServiceMock;import cn.com.sitefromscrath.service.SearchServiceInRealBiz;public class BeanFactory { public static boolean MOCK = true; public static Object getBean(String id) { if("searchService".equals(id)) { if(MOCK) { return new SearchServiceMock(); } else { return getSearchService(); } } throw new RuntimeException("cannot find the bean with id :" + id); } public static LuceneDAO getLuceneDAO() { if(MOCK) { return new LuceneDAOMock(); } else { throw new RuntimeException("cannot find the LuceneDAO bean"); } } public static MysqlDAO getMysqlDAO() { if(MOCK) { return new MysqlDAOMock(); } else { throw new RuntimeException("cannot find the MysqlDAO bean"); } } public static SearchService getSearchService() { if(MOCK) { return new SearchServiceMock(); } else { return new SearchServiceInRealBiz(); } } public static void main(String ... arg) { String keywords = "test"; SearchService searchService = (SearchService)BeanFactory.getBean("searchService"); List results = searchService.search(keywords); for(int i = 0; i < results.size(); i++) { Result result = (Result) results.get(i); System.out.print("[" + result.title + "]"); System.out.println(result.content); } }} 測试无误。bingo! I gotta get the GREEN BAR!
!!(JUnit专用~~~)
如今,我開始发现
BeanFactory有点儿无处不在了,一旦须要改动。哪怕是改个 BeanFactory 的名字,假设没有refactor工具,工作也是相当麻烦的。
这就是所谓的 “上帝类 God Class” “上帝对象 God Object”
为了降低影响。至少,我应该尽可能的把 BeanFactory 的字样从其它类里面移出去。
让我们高唱国际歌,“从来就没有什么救世主,也没有神仙皇帝”,对BeanFactory进行大刀阔斧的革命~~。
在我们如今的代码里,仅有 SearchServiceInRealBiz 拥抱了 “上帝”。 因此。想想办法:
public class SearchServiceInRealBiz implements SearchService { private LuceneDAO luceneDAO; private MysqlDAO mysqlDAO; private SearchServiceInRealBiz(LuceneDAO luceneDAO, MysqlDAO mysqlDAO) { super(); this.luceneDAO = luceneDAO; this.mysqlDAO = mysqlDAO; } public List search(String keywords) { int[] idlist = luceneDAO.findDocIDs(keywords); List results = mysqlDAO.getResultsByDocIDs(idlist); return results; }} 当然 BeanFactory 肯定会报错的。 
必须说明:我期待这种报错(编译时报错),这样我们才干发现对代码进行调整之后会影响那些地方。然后随之做出相应调整。
參考第二种方式:
private LuceneDAO luceneDAO; private MysqlDAO mysqlDAO; public void setLuceneDAO(LuceneDAO luceneDAO) { this.luceneDAO = luceneDAO; } public void setMysqlDAO(MysqlDAO mysqlDAO) { this.mysqlDAO = mysqlDAO; } public List search(String keywords) { int[] idlist = luceneDAO.findDocIDs(keywords); List results = mysqlDAO.getResultsByDocIDs(idlist); return results; } 这样eclipse不会报错。可是。。 。。。。。你失去了改正的机会。
混过了编译时检測,跑不掉执行时报错D,亲!
并且。这个问题会隐蔽的让你吐血~~~~
(事实上,我在暗示你应该在spring的xml中选择哪一种装配方式……)
如今。让我们修复BeanFactory 的报错:
public static SearchService getSearchService() { if(MOCK) { return new SearchServiceMock(); } else { LuceneDAO luceneDAO = getLuceneDAO(); MysqlDAO mysqlDAO = getMysqlDAO(); return new SearchServiceInRealBiz(luceneDAO, mysqlDAO); } } RUN一次,ok,没有问题。 I LOVE GREE BAR!

《儿歌三百首》绝非浪得虚名~~
to be continued....